https://twitter.com/karpathy/status/1781028605709234613
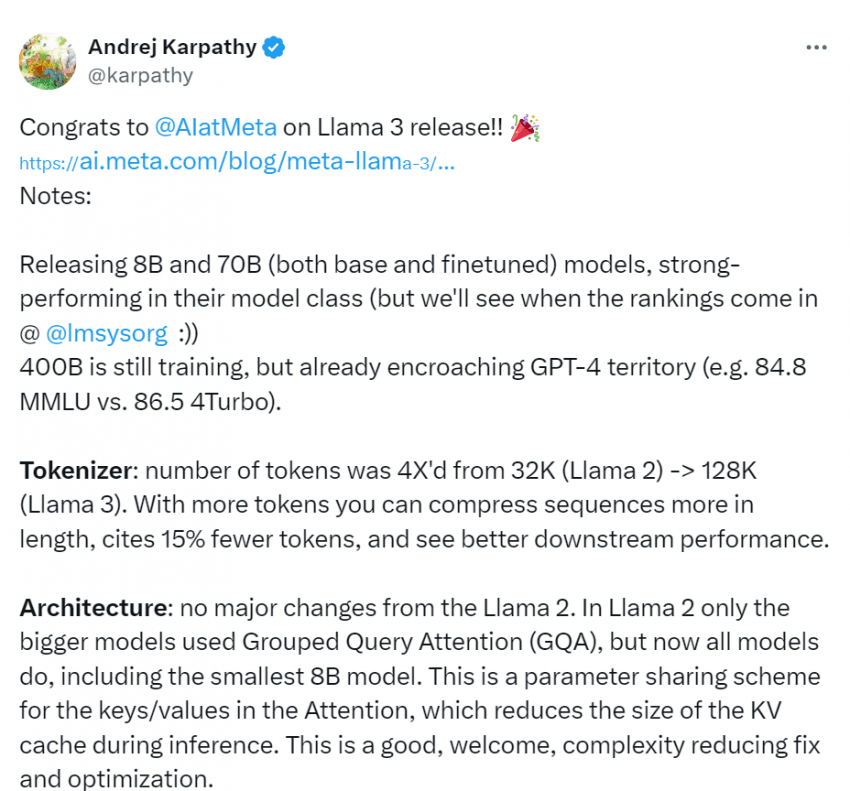
- 8B, 70B(기본 모델과 파인튜닝된 모델 모두) 모델을 공개함. 이들은 각 모델 클래스에서 강력한 성능을 보여줌.
- 400B 모델은 아직 학습 중이지만, 이미 GPT-4의 영역에 근접하고 있음(예: MMLU 84.8 vs. GPT-4의 86.5)
토크나이저
- 토큰 수가 32K(Llama 2)에서 128K(Llama 3)로 4배 증가
- 더 많은 토큰으로 시퀀스 길이를 더 압축할 수 있음. 15% 적은 토큰을 인용하고 다운스트림 성능 향상
아키텍처
- Llama 2에서는 큰 모델만 Grouped Query Attention(GQA)를 사용했지만, 이제 가장 작은 8B 모델을 포함한 모든 모델이 GQA를 사용
- GQA는 Attention의 키/값에 대한 파라미터 공유 체계로, 추론 중 KV 캐시의 크기를 줄임
- 이는 복잡성을 줄이고 최적화하는 좋고 환영받을 만한 수정사항임
시퀀스 길이
- 컨텍스트 윈도우의 최대 토큰 수가 4096(Llama 2) 및 2048(Llama 1)에서 8192로 증가
- 이 증가는 환영할 만하지만 최신 표준(예: GPT-4는 128K)에 비해 상당히 작음
- 많은 사람들이 이 축에 대해 더 많은 것을 기대했을 것임. 나중에 파인튜닝으로 가능할지도(?)
학습 데이터
- Llama 2는 2T 개의 토큰으로 학습되었고, Llama 3은 15T 학습 데이터셋으로 증가
- 데이터 품질, 4배 더 많은 코드 토큰, 30개 이상의 언어로 5%의 non-en 토큰에 많은 주의를 기울임
- 5%는 non-en:en 믹스에 비해 상당히 낮아서 이 모델은 대부분 영어 모델임. 그러나 0보다 큰 것은 꽤 좋음
스케일링 법칙
- 15T는 8B 매개변수와 같은 "작은" 모델에 대해 학습하기에 매우 큰 데이터셋이며, 이는 일반적으로 수행되지 않는 새롭고 매우 환영할 만한 일임
- 친칠라 "compute optimal" 포인트에서 8B 모델을 학습시키려면 ~200B 토큰 정도 학습시켜야 함
- 모델 성능에 대한 "bang-for-the-buck"에만 관심이 있다면 이 정도면 충분함
- 하지만 Meta는 그 지점을 ~75배 넘어 학습시켰는데, 이는 비정상적이지만 개인적으로 매우 환영할 만한 일이라고 생각함.
- 우리 모두는 매우 작고 작업하기 쉬우며 추론이 쉬운 매우 유능한 모델을 얻게 됨
- Meta는 이 지점에서도 모델이 표준적인 의미에서 "수렴"하는 것 같지 않다고 언급함
- 즉, 우리가 항상 작업하는 LLM은 100-1000배 이상의 훨씬 더 긴 학습이 부족하며 수렴점에 근접하지 않음
- 앞으로 더 오랫동안 학습되고 훨씬 더 작은 모델을 공개하는 추세가 계속되기를 바람
시스템
- Llama 3는 16K GPU에서 관찰된 처리량이 400 TFLOPS로 학습되었다고 언급됨
- 언급되지는 않았지만 이들이 NVIDIA 마케팅 자료에서 1,979 TFLOPS를 기록하는 H100 fp16이라고 가정
- 하지만 우리는 모두 그들의 작은 별표(*with sparsity)가 많은 일을 하고 있다는 것을 알고 있으며, 실제 TFLOPS를 얻으려면 이 숫자를 2로 나누어 ~990을 얻어야 함
- (Sparsity가 FLOPS로 계산되는 이유는 무엇일까?)
- 어쨌거나 400/990 ~= 40% 활용률로, 그 많은 GPU에서 꽤 나쁘지 않음!
- 이 규모에서 여기에 도달하려면 많은 양의 정말 탄탄한 엔지니어링이 필요함
요약
- Llama 3는 매우 유능해 보이는 모델 릴리스이며 매우 환영할 만함
- 기본에 충실하고, 탄탄한 시스템과 데이터 작업에 많은 시간을 할애하며, 장기 학습 모델의 한계를 탐구함
- 400B 모델도 매우 기대되며, 이는 GPT-4 급의 첫 번째 오픈 소스 릴리스가 될 수 있음
- 많은 사람들이 더 긴 컨텍스트 길이를 요구할 것이라고 생각함









{kind=link}
댓글 영역
획득법
① NFT 발행
작성한 게시물을 NFT로 발행하면 일주일 동안 사용할 수 있습니다. (최초 1회)
② NFT 구매
다른 이용자의 NFT를 구매하면 한 달 동안 사용할 수 있습니다. (구매 시마다 갱신)
사용법
디시콘에서지갑연결시 바로 사용 가능합니다.