https://github.com/microsoft/unilm/tree/master/bitnet
마이크로소프트 언어모델 관련 깃허브에 오늘 추가 자료 올라옴
The Era of 1-bit LLMs: Training Tips, Code and FAQ
그리 길지는 않아서 전체적으로 보고 왔음

저자들도 회의적인 반응들이 꽤 있어서 그랬는지,
논문에 'Believing is seeing.' 이라고 박아 놓음
(직접 보면 안 믿을 수 없을 것이다.)
어떻게 학습했는지와 학습 과정에 대한 보다 구체적인 자료, 하이퍼파라미터 등 공개하고
어떻게 파이토치로 구현하는지도 공개함
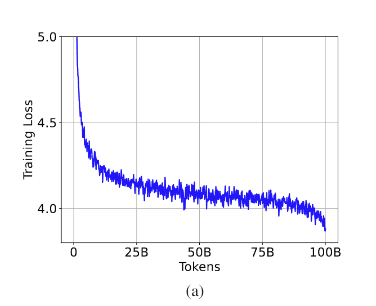
이번 보고서에서 공개한 그래프
저자들은 1.58 BitNet이 S자형 손실 곡선을 보여준다고 말함
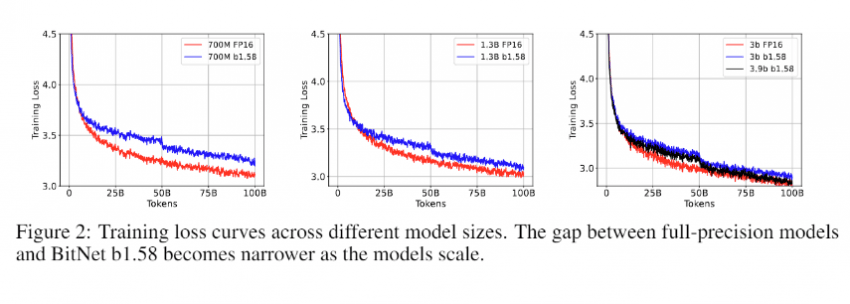
그리고 이 그래프가 이 보고서의 핵심이라고 볼 수도 있는데,
모델 크기가 커지면 커질 수록 전체 정밀도 모델과 학습 손실 차이가 줄어드는 경향을 보여줌
아래는 저자들이 써놓은 FAQ
1. 삼항 {-1, 0, 1} 말고 딴건 왜 안씀?
{-1, 1} : 원래 BitNet b1(저자들의 이전 논문)에서 구현이었는데 성능이 삼항보다 딸렸음
{0, 1} : 최적화가 매우 불안정함
{-2, -1, 0, 1} or {-2, -1, 0, 1, 2}같이 추가적인 비트 사용 : 삼항 {-1, 0, 1}하고 별 차이 없어서 안씀
2. 훈련도 빨라짐?
현재 구현은 여전히 FP16/BF16에 있어서 실험에서 실제 속도 향상은 없음
하지만 대형 모델의 경우 가속화할 수 있는 상당한 기회가 있음
3. BitNet이 더 큰 모델에도 작동함?
"The Era of 1-bit LLMs" 논문에서 공개한 것처럼 완전 정밀도 LLM과 BitNet 1.58 사이의 간격이 모델 크기가 커짐에 따라 작아지는 것을 보여주는 명확한 추세가 있음
이는 BitNet이 더 큰 모델에 더욱 효과적이라는 것을 의미함
오히려 BitNet은 더 큰 모델 크기에서 더 나은 성능을 발휘함
1.58 비트 모델은 더 나은 일반화 기능을 제공하고 과적합이 덜 발생할 수 있음
그리고 아래에 파이토치 기반 구현 코드도 공개했는데, 되게 간단해서 금방 사람들이 실험해볼 듯
이번에도 여전히 저자들의 주장이기는 하나
저자들은 믿음이 굉장히 굳건해보인다.
끗









{kind=link}
{kind=link}
{kind=link}
{kind=link}
댓글 영역
획득법
① NFT 발행
작성한 게시물을 NFT로 발행하면 일주일 동안 사용할 수 있습니다. (최초 1회)
② NFT 구매
다른 이용자의 NFT를 구매하면 한 달 동안 사용할 수 있습니다. (구매 시마다 갱신)
사용법
디시콘에서지갑연결시 바로 사용 가능합니다.