https://www.aitimes.com/news/articleView.html?idxno=158785

인공지능(AI) 모델의 성능을 평가하는 '벤치마크'가 변하고 있다. 수년간 사용한 기존 벤치마크의 효용성이 떨어졌다는 지적에 이어, 최근에는 급속도로 발전한 모델에 맞춘 새로운 평가 수단이 등장하고 있다.
파이낸셜 타임스는 10일(현지시간) AI 개발 속도가 급격하게 빨라지며 평가 수단이 이를 따라가지 못하고 있다고 지적했다.
이에 따르면 AI 모델은 최근 1년간 급격하게 성능이 향상하고 있으며, 이에 따라 새로운 모델이 등장할 때마다 기존 모델을 앞질렀다는 발표가 따르고 있다.
실제로 구글은 지난 1월 '제미나이 1.0'을 선보이며, 벤치마크에서 오픈AI의 'GPT-4'를 대부분 능가했다고 발표했다. 이어 3월 초에는 앤트로픽이 '클로드 3'를 출시하며 GPT-4는 물론 제미나이까지 앞섰다고 밝혔다.
지난주에는 같은 일이 2차례나 발생했다. 오픈AI는 12일 GPT-4 업그레이드 버전을 발표하며 나머지 두 모델을 벤치마크에서 능가했다고 공개했으며, 같은 날에는 xAI가 첫 멀티모달모델(LMM) '그록-1.5V'를 공개하며 기존 'GPT-4V'와 클로드 3, 제미나이 1.5 프로 등 LMM을 일부 능가했다고 전했다.
오픈 소스에서는 이런 현상이 더욱 심하다. 허깅페이스의 오픈 LLM 리더보드에서 1위를 차지한 모델이 세계적인 관심을 받게 됨에 따라, 이제는 기업들이 정상을 두고 쟁탈전을 벌이고 있다. 국내의 업스테이지나 투디지트, 모레, 솔트룩스 같은 기업들도 참가, 정상을 차지한 바 있다.
이에 대해 제시 도지 앨런 AI 연구소 과학자는 "AI 업계가 평가 위기에 도달했다"라고 단정했다.
그는 테크크런치와의 인터뷰에서 "기존 벤치마크는 단일 기능 평가에 좁게 초점이 맞춰져 있다"라며 "대부분은 AI 시스템이 주로 연구에만 사용됐고 실제 사용자가 많지 않았던 3년 이상 된 것"이라고 설명했다.
또 "사람들이 생성 AI를 사용하는 다양한 방법과는 동떨어져 있으며, 일부 벤치마크 항목은 원래 기능에 부합하는지도 의문"이라고 말했다. 그 대안으로 인간 참여를 높이는 방법도 제시했다. "올바른 길은 벤치마크와 인간 평가를 결합하는 것"이라며 "실제 사용자 쿼리로 응답이 얼마나 좋은지 평가해야 한다"라고 말했다.
에이단 고메스 코히어 CEO도 이에 동의했다. 그는 "공개 벤치마크에는 수명이 있다"라며 “모델을 최적화하거나 평가하는 데 몇년 동안은 유용했지만, 이제는 유효 기간이 몇달로 줄었다"라고 지적했다.
그 이유로 "기존 벤치마크를 완전히 능가할 수 있는 새로운 AI 시스템이 정기적으로 등장한다"라며 "모델이 향상됨에 따라 이런 평가는 더 이상 쓸모가 없게 된다"라고 밝혔다.
이에 따라 최근에는 새로운 벤치마크가 속속 등장하고 있다.
기존에는 모델의 🔼추론(ARC) 🔼상식(HellaSwag) 🔼언어이해력(MMLU) 🔼환각방지능력(TruthfulQA) 🔼수학적 추론(GSM8K) 🔼상식 추론(WinoGrade) 등 허깅페이스 ‘H6’ 지표가 대표적이었다. 여기에 🔼코딩 능력을 판단하는 휴먼 이밸(HumanEval) 🔼대화능력 지표 ‘MT-벤치(MT-bench)’ 🔼감성평가 지표 ‘EQ-벤치’ 🔼지시이행 능력 지표 ‘IF이밸(IFEval)’ 등이 주로 활용됐다.
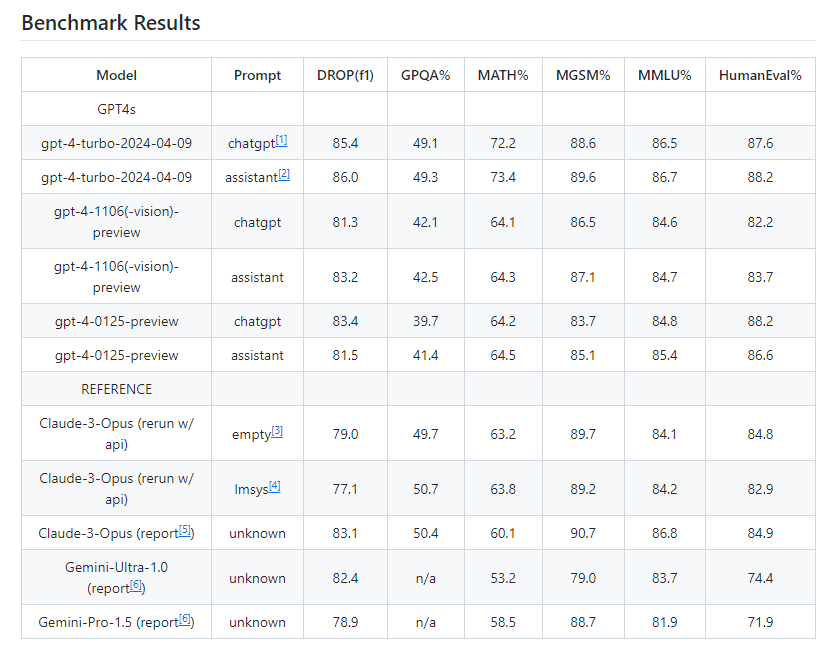
그러나 오픈AI는 최신 'GPT-4 터보'를 공개하며 🔼MATH(수학적 문제 해결 측정) 🔼GPQA(대학원 수준의 구글 증명 Q&A 벤치마크) 🔼DROP(단락에 대한 이산적 추론이 필요한 독해 벤치마크) 등의 항목을 추가했다.
또 멀티모달모델이 늘어나며 이제까지는 볼 수 없었던 새로운 타입의 새로운 벤치마크도 속속 등장하고 있다. 특히 지난 주말에는 메타와 xAI가 나란히 자체 개발한 LMM용 벤치마크 데이터셋을 공개했다.
우선 메타는 주변 환경 이해를 측정하는 도구로, 집과 사무실 등 180개 이상의 다양한 실제 환경에 대한 1600개 이상의 질문이 포함된 벤치마크 데이터셋 ‘오픈EQA(OpenEQA)’을 오픈 소스로 공개했다.
이어 xAI 역시 실제 공간 이해 기능을 평가하기 위해 개발한 '리얼월드Q&A'를 출시했다. 여기에는 700개 이상의 이미지와 이에 대한 질문과 답변이 포함돼 있다.
특히 두 회사는 AI 모델이 텍스트 위주의 학습을 뛰어넘어 물리적인 실제 세계를 이해하도록 하는 것이 AGI를 달성하는 새로운 방법이라고 강조했다.
이 밖에도 아예 인간이 직접 챗봇을 블라.인드 테스트하고 선호도를 평가하는 '챗봇 아레나(Chatbot Arena)'라는 LLM 리더보드도 빠르게 인기를 얻고 있다. 심지어 지난주 화제를 모은 미스트랄AI의 LLM '스트리트 파이터3' 대회도 게임 능력을 테스트하는 일종의 벤치마크라는 설명이다.











{kind=link}
{kind=link}
댓글 영역
획득법
① NFT 발행
작성한 게시물을 NFT로 발행하면 일주일 동안 사용할 수 있습니다. (최초 1회)
② NFT 구매
다른 이용자의 NFT를 구매하면 한 달 동안 사용할 수 있습니다. (구매 시마다 갱신)
사용법
디시콘에서지갑연결시 바로 사용 가능합니다.