https://www.aitimes.com/news/articleView.html?idxno=158958

메타가 입력 데이터가 커질수록 추론이 느려지고 메모리 공간이 많이 필요한 '트랜스포머' 아키텍처의 약점을 보완한 새로운 대형언어모델(LLM)을 공개했다.
벤처비트는 18일(현지시간) 메타와 미국 남가주 대학(USC) 연구진이 막대한 양의 메모리를 요구하지 않고도 컨텍스트 창을 수백만개의 토큰으로 확장 가능한 LLM ‘메갈로돈(Megalodon)’에 관한 논문을 온라인 아카이브에 게재했다고 전했다.
'챗GPT'나 '제미나이' 등 LLM에 사용되는 트랜스포머 아키텍처는 컨텍스트 창이 커짐에 따라 필요한 메모리와 계산 시간이 기하급수적으로 증가하는 단점이 있다. 예를 들어, 입력 크기를 토큰 1000개에서 2000개로 확장하면 입력을 처리하는 데 필요한 메모리와 계산 시간이 두배가 아닌 네배로 늘어나게 된다. 이는 텍스트 내 토큰들의 상관관계를 밝혀내기 위해 입력 정보를 병렬로 처리하는 '어텐션 메커니즘' 때문이다.
메갈로돈은 2022년에 처음 발표된 '메가(MEGA)' 기술을 기반으로 구축됐다. 메가는 모델의 복잡성을 크게 줄이는 방식으로, 어텐션 메커니즘을 수정하여 LLM이 메모리 및 계산 요구 사항을 폭발시키지 않고도 더 긴 입력을 처리할 수 있게 한다.
메갈로돈은 입력 시퀀스를 고정 크기 블록으로 나누어 모델 복잡도를 선형으로 줄이는 '청크별 어텐션(chunck-wise attention)'으로 메가를 개선했다. 청크별 어텐션을 사용하면 모델 학습 속도도 크게 향상된다.
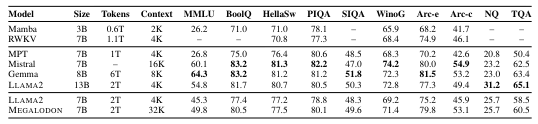
연구진에 따르면 2조 토큰의 데이터셋으로 훈련한 70억 매개변수의 메갈로돈-7B 모델은 '라마-2-7B' 및 '13B' 등과의 벤치마크에서 앞선 성능을 기록했다. 훈련 복잡성과 다운스트림 벤치마크에서 라마 2-7B보다 훨씬 뛰어난 성능을 기록했으며 일부 작업에서는 라마-2-13B와 동등한 성능을 보였다.
또 4000 토큰 컨텍스트 창에서 메갈로돈은 라마-2보다 약간 느리지만 3만2000 토큰으로 컨텍스트 길이를 확장하면 메갈로돈이 계산 효율성 때문에 라마-2를 크게 앞서는 것으로 나타났다. 긴 컨텍스트 모델링에 대한 실험 결과 메갈로돈이 무제한 길이의 시퀀스를 모델링할 수 있음을 시사한다고 주장했다.
현재 메갈로돈은 깃허브에서 제한 없이 상업적 목적으로 무료 사용 가능하다.
한편 4월에만 트랜스포머 아키텍처의 약점을 보완하기 위한 새로운 기술이 잇달아 공개되고 있다.
이스라엘 스타트업 AI21 랩스는 SSM을 기반으로 하는 ‘맘바(Mamba)’와 트랜스포머 아키텍처의 최고의 특성을 결합한 LLM ‘잠바(Jamba)’를 출시했다. 구글은 이번 주 LLM 컨텍스트 창 길이를 무한확장할 수 있는 ‘인피니-어텐션(Infini-attention)’ 기술을 공개했다.
이 외에도 스타트업 심볼리카는 트랜스포머 아키텍처에 기반한 LLM을 실행하는데 많은 비용이 드는 문제를 해결하기 위해 기호(Symbols)를 조작해 작업을 정의하는 ‘심볼릭 AI(Symbolic AI)’ 기법을 도입했다.











{kind=link}
{kind=link}
댓글 영역
획득법
① NFT 발행
작성한 게시물을 NFT로 발행하면 일주일 동안 사용할 수 있습니다. (최초 1회)
② NFT 구매
다른 이용자의 NFT를 구매하면 한 달 동안 사용할 수 있습니다. (구매 시마다 갱신)
사용법
디시콘에서지갑연결시 바로 사용 가능합니다.