
일단 첫 언급은 chatgpt가 슬슬 나온 2022년 말 삼전 네이버 반도체 협업 mou
물론 이후 관련자 말들어보면 이전부터 협업은 계속 했던 모양
하이퍼클로바 성능 쓰레기 인건 논외로 하더라도 라마 같은 오픈소스 모델 수정이 아니라 완전 자사 데이터셋으로
모델 설계부터 학습 그리고 소비자한테 직접 서비스까지 한 회사에서 하는건 진짜 드문게 맞음 당연히 여러 노하우도 일반 반도체 스타트업보다는 많을거고
그런 모델 관점과 실제 추론서비스의 노하우를 삼성과 협업하며 전용 칩셋 만들기 프로젝트 시작함
본격적으로 세부사항이 공개된건 작년 12월 과학기술정보통신부 주최로 열린 ‘제4차 AI반도체 최고위 전략대화’
https://www.sedaily.com/NewsView/29YKMLUDQM
일단 fpga로 컨셉 실현 확인 수준이였고 라마 33b 자사 하이퍼클로바x 그리고 네이버 거대 비전 모델 하루만에 돌렸다고함
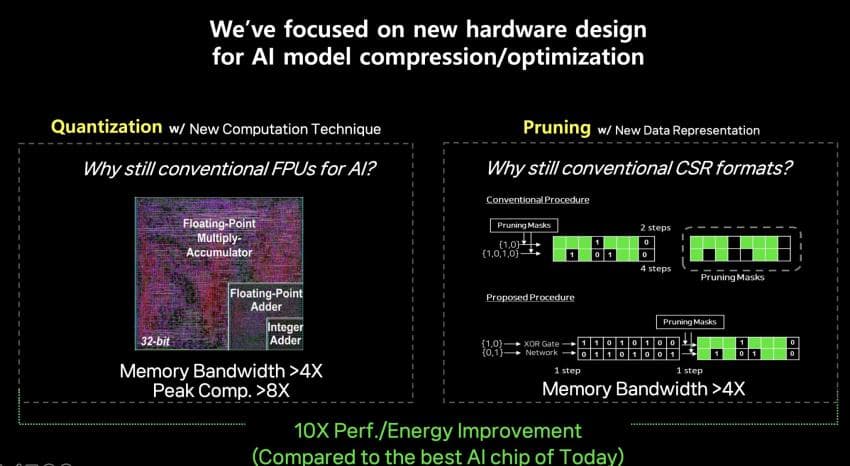
주된 컨셉은 Pruning과 Quantization 나중에 후술하겠음

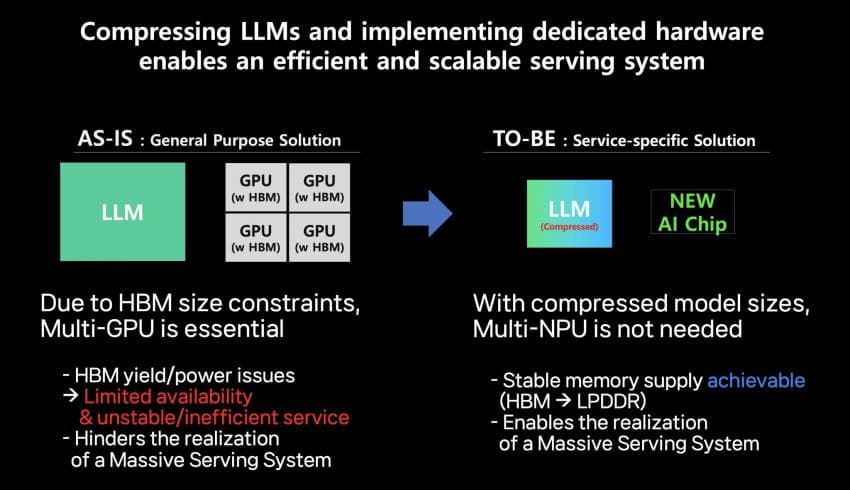
가장 큰 특징은 마치 오디오나 영상데이터 처럼 ai 연산에 압축을 도입하겠다는것이다 이로서 메모리 사용량을 대폭 줄이고 유효대역폭을 늘림으로서
ㅈ도 비싼 2.5d 패키징 hbm 안쓰고 추론 하겠다는 것이다 특히 이러면 한칩에 큰 모델을 올릴수 있기 때문에 큰모델을 여러 gpu에 나눠 추론하며
기하급수적으로 효율성이 박살나는것을 막을수 있다 (최대 한칩에 250b까지라고 주장)
참고로 b100 h100 추론 30배도 이런 상황을 이용해 h100 64개 분산 추론이라는 억까 상황을 도입해서 황회장식 벤치로 달성한 수치(물론 엔비디아는 개쩌는게 맞다)
어쨋든 위짤에서 A company는 우리가 너무나 잘아는 a100 X 2개이고 B company는 구글 TPU X 5개이다
네이버는 이 상황에서 토큰당 40MS 이하로 대충 전성비 8배라고 "주장"하고 있다

다행이 네이버는 세미콘 코리아에서 더 자세한 내용을 공개한 바 있다
칩은 대충 150W 먹고 라마2 70B GQA 기준 입력 토큰 출력 토큰 각각 1024, 배치 사이즈 "32" 기준 짤 수치대로 계산하면 대충 초당 857토큰 나온다!?
물론 GQA 아닌 라마 65B는 초당 376토큰으로 대폭 줄긴하지만 대단한 수치이다 뭔소리인지 모를테니 바로 비교군을 가지고 와보자
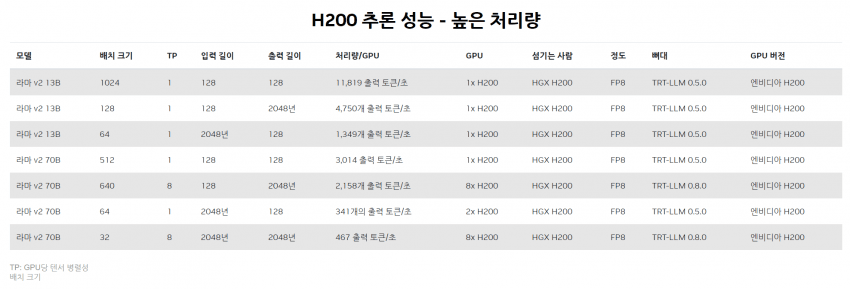
https://developer.nvidia.com/deep-learning-performance-training-inference/ai-inference
아직 출시도 못한 H200이다 우리가 항상 추종하는 H100이 아니다
GQA 적용인지 아닌지 모르겠지만(아마 아닐듯) 맨아래 8대? H200 모아서 32 배치 사이즈로 467토큰/초당 이 나온다 ㄷㄷ
물론 입출력 토큰이 무려 각각 두배고 GQA도 아닐꺼라 매우매우매우 불리한 비교이긴 하지만 H200는 대당 3만달러에 700W 처먹는 놈이라는것을 기억해주자
그러면 어떻게 ㅈ도 못믿음직스러운 국내기업따리가 이런 말도 안되는 일을 했다고 주장하는 것일까?
분명 엔비디아가 ㅄ도 아니고 모델 만드는 놈들 Pruning과 Quantization는 밥먹듯이 하는건데 사기 아님?
GPU에서도 똑같이 하면 되는거자나 라고 생각할 수 있다 그에 대한 대답은 네이버 쪽 개발자의 글에서 가져와보았다
https://www.facebook.com/dongsoo.lee.104
1. Pruning에서의 문제: 비균일한 압축결과물
Pruning은 쉽게 얘기하자면 불필요한 parameter들을 제거하는 방법이라고 할 수 있습니다. 예를 들면 100개 parameter중에서 50개를 0으로 처리해버리고 메모리에서 무시하면 압축률은 2배가 됩니다. 0으로 만들어도 되는 parameter가 넘쳐난다 라는 이론은 Lottery Ticket Hypothesis 등에서 확인된 부분들이고 이미 경량화 하는 사람들은 누구나 알고있습니다 (사실 심지어 pruning을 적절히 하면 압축했음에도 성능이 올라갑니다, 복잡한 이론이라 생략하겠습니다만 이렇게 0이 되어도 괜찮은 parameter가 존재하는것이 오늘날 딥러닝 학습이 가능한 근간이기도 합니다) 여기서 큰 문제점이 pruning을 원래 이론대로 제대로 적용하면 AI 모델의 압축률이 전체 모델 구석구석에서 균일하지 않다는 점입니다. 예를 들면 100개씩 parameter들을 잘라서 각각을 보면 살아남는 개수가 100개중에서 25개, 35개, 67개, 12개… 이렇게 제각각입니다 (pruning 할 수 있는 paramter개수가 random하고 뭔가 정형화된 패턴이 없다는 것은 전에 말씀드린 inductive bias가 적어지는 부분과 일맥상통하는 부분들이 꽤 많습니다) 이렇게 제각각의 개수가 살아남는 pruning방법을 unstructured pruning이라고 하고 pruning 알고리즘의 근간입니다.
잘 아시다시피 GPU를 비롯한 병렬처리 근간의 반도체는 이렇게 100개씩 묶은 데이터들을 한꺼번에 동시다발적으로 처리를 할 수 있다는 점입니다. 그런데, 만일 4개의 계산 유닛이 위와 같이 25개, 35개, 67개, 12개.. 각기 다른 숫자의 데이터 양을 처리하면 어떻게 될까요? 가장 일을 많이 해야하는 67개를 받은 유닛이 계산을 다 끝낼때까지 다른 3개의 계산유닛은 기다려야 합니다. 즉, 많은 유닛친구들은 상당시간 놀아야합니다. 결국 가장 느린 녀석 떄문에 전체가 기다려줘야하는데요, 만일 100개씩 묶은 다발의 개수가 점점 더 많아진다면? 복잡한 통계를 가져다 쓰지 않더라도 최악의 조건이 되는 숫자는 점점 더 클 것이라는 예상을 할 수 있습니다. 그래서 GPU가 발전하여 점점 계산 유닛이 내부에 많아질수록 이렇게 unstructured pruning의 성능은 점점 떨어져버립니다 (위의 예를 들자면 결국 전체 블록이 모두 67개 살아남았다고 가정할때와 비교하여 속도 차이는 없어져버리니는 겁니다. 나머지는 2개만 남던 10개만 남던, 67개 끝날때까지 기다리는것이니까요) 게다가 그렇게 비싼 HBM 메모리도 같이 놀고 있어야한다는 문제점이 가장 큽니다.
GPU는 모든 계산기들과 메모리들이 균일한 양의 일을 해야한다는 가정하에 발전을 키워온것인데, pruning과 궁합이 근본적으로 안맞는거죠.
문제는 여기서 그치지 않습니다. 각 100개 크기의 블록마다 몇개가 살아남았는지도 기록을 해야하기도 하고, 관리가 복잡해집니다. 즉 이렇게 불균일한 압축방식은 GPU 같이 대규모로 병렬처리를 해야하는 반도체에서 매우 불리합니다.
어느 정도로 불리하냐면 전체 압축률이 90%에 달하더라도 압축 안한것보다 느립니다 (최신 GPU는 95% 압축을 해도 느립니다) 앞서 말씀드린 바와 같이 GPU내에 계산기가 많아질수록 경량화에는 불리한 아이러니가 생겨버립니다. 10개의 랜덤한 숫자중에서 가장 큰 숫자를 뽑는것과 10000개의 random한 숫자 중에서 가장 큰 숫자를 뽑는 것을 비교해보시면 아실 수 있죠. 그래도 압축인데 어떻게 더 느려질 수가 있느냐? 불균일한 데이터 구조를 관리하기 위한 추가관리회로가 크게 들어가기 때문입니다 (살아남은 parameter 하나하나의 위치를 일일이 기록해야한다는게 가장 크긴합니다). 90% pruning이면 100개 중에 평균 10개만 살아남아야하는데, AI 모델은 학습시켜놓고 보면 워~낙 예측이 안되는 녀석이라, 어떤 나쁜 블록은 거의 90개나 살아남아 버리는 상황이 얼마든지 나올 수가 있고 최악의 상황은 동시처리 블록수가 많아질수록 더 잘 발생하며, 이러한 나쁜 극소수 블록들이 전체 성능을 죄다 잡아먹는 일이 다반사입니다.
삼성전자/네이버 반도체에서는 이 문제를 해결하기 위해 압축을 진행한 뒤에 전체 parameter들을 encryption 시켜버렸습니다 (5G 통신 기술 같은게 들어갑니다) 그래서 압축을 진행한 뒤에 거의 대부분의 블록에서 살아남은 parameter 개수를 통일시켜버립니다. block마다 살아남은 parameter 개수가 상당히 균질해지기 때문에 위와 같은 문제가 없고 거의 압축한만큼 (특히 메모리) 성능이 개선되는 효과를 볼 수 있습니다.
2. Quantization 문제 (메모리와 계산기가 원하는 형식의 불일치)
Quantization은 길게 쓰면 너무 복잡해져서 짧게만 쓰자면, 모델이 커지면서 특히 Transformer같은 모델들이 등장하면서 activation의 압축이 굉장히 어려워졌습니다. LLM에 오면 특히나 activation이 관리가 안되는데요, 잠잠 하다가 어떤 특정 상황이 되면 평소보다 2만배 더 큰 숫자가 activation에서 불쑥 튀어나기도 하고 softmax같은 비선형 수식을 지나가면서 또 다시 숫자가 불균일해지는 등, activation 압축은 매우 어렵습니다.
그래서 요즘은 weight-only quantization을 많이 합니다. 즉, 메모리에 저장해야하는 weight만이라도 잘 줄이면 memory bandwidth도 몇배로 더 잘 쓸 수 있고 메모리 용량도 훨씬 더 효율적으로 쓸 수 있겠다 하는 아이디어입니다.
그런데 불행하게도 이렇게 되면, 메모리에 저장된 weight의 형식과 실제 계산에 이용되는 weight의 형식이 불일치가 되는 문제가 있습니다. 즉, activation은 압축이 안되어있는 것이라 weight도 결국 압축을 풀어야합니다. 그래야 activation과 weight이 만나서 계산이 이루어질 수 있으니까요. 이 때 weight 압축을 풀어내는 형태가 또 GPU에 잘 안맞는 경향이 생깁니다. 복잡하긴한데 이 또한 GPU의 설계 특성과 안맞는 부분들이 많기 때문인데요, batch size가 커질수록, 즉 계산을 많이 해야할수록 weight의 압축을 풀어내는 데 필요한 추가 계산량이 상대적으로 점점 더 커져버려서 결국 또… 압축 안한것보다 느린 결과를 보이게 됩니다.
삼성/네이버에서는 압축된 weight과 압축 안한 activation이 만나서 효율적인 계산이 가능하도록 회로를 만들었습니다. 이렇게 되면 weight 압축을 풀지 않아도 되는 장점은 물론, 계산기도 극단적으로 단순화 시킬 수 있다는 ‘발견’을 하였습니다. 저희처럼 FPU같은 근본 계산기도 AI에 맞게 뜯어고칠 수 있는 풀스택 엔지니어들이 존재하기 때문에 가능했습니다 (가장 먼거리에 있는 계산기 회로 설계자와 AI 경량화 SW엔지니어가 같이 고민을 한가죠. 원래 이 두사이는 만날일이 좀처럼 없고 협력 포인트 찾기도 어렵습니다)
일부만 발췌해왔으니 가서 읽어보자
어쨋든 이렇게 열심히 만들고 있는 "마하1"은 올해말 FPGA에서 벗어나 SOC로 만들고 내년 초 시스템 완성이라는 일정을 가지고 있고
마하 1이라는 이름에서 알 수 있듯 향후 후속작도 최근 삼성이 신설한 AGI 컴퓨팅랩에서 후속 칩을 계속 이어갈 예정?이다
참고로 AGI 컴퓨팅랩 대빵으로 채용해온 우동혁 박사는 2014년 이후로 구글에서 10년동안 TPU를 제작한 주요 인재로 알려져 있음
https://www.blockmedia.co.kr/archives/486852
그리고 공동 개발자이자 첫고객인 네이버가 1조에 15만~20만 개 지를것 같다 개당 500만원꼴인듯?
https://www.hankyung.com/article/2024032175811
https://www.hankyung.com/article/2024032175811
삼성, 주총서 깜짝 공개한 '비밀병기'…1조 잭팟 터졌다
삼성, 주총서 깜짝 공개한 '비밀병기'…1조 잭팟 터졌다, 삼성, 네이버에 AI 가속기 1兆 공급 추론 서버 엔비디아 제품 대체 가격은 10분의 1, 전력효율 8배
https://img.hankyung.com/photo/202403/AA.36194961.1.jpg
그리고 최근 한국 왔던 이 두 사람도 해당 내용을 보고 갔을 확률이 매우매우 높다

물론 특갤러들이 국내 기업들 불신하는건 아주아주 잘 알고 있다
그런데 현실적으로 지구상에 반도체 종합적으로 하는 회사도 있고 LLM도 ㅈ구리지만 자체 학습하고 자체 서버에서 "서비스"까지 한 노하우 가진 기업이
자국에 동시에 있는 나라가 얼마나 된다고 생각함? 진짜 존나 드물다 거기에 두 회사가 협력하는건 더 드물고
뭐 기대를 하라 응원을 하라 뭐 이런 소리까지는 아닌데 너무 내려치기 할것까지는 없고 내년 결과 나오는거까지 봐주는게 좋지 않을까? 라는게 나의 생각이다
긴글 봐줘서 고맙다












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
댓글 영역
획득법
① NFT 발행
작성한 게시물을 NFT로 발행하면 일주일 동안 사용할 수 있습니다. (최초 1회)
② NFT 구매
다른 이용자의 NFT를 구매하면 한 달 동안 사용할 수 있습니다. (구매 시마다 갱신)
사용법
디시콘에서지갑연결시 바로 사용 가능합니다.