어제 12화를 보고 머릿속으로 정리를 좀 하고나서 오늘 올립니다
CSAPP 수업을 듣거나 책을 읽지 않고, 이 과목을 들은 적 없는 사람들을 위해서
필요없는 부분은 최대한 쳐내고 가장 쓸모 있는 부분과 코딩 팁들을 정리해서 올립니다.
이전화 바로가기
-------------------------------------------------------------
C/C++에서 아주 간단한 최적화...
https://gall.dcinside.com/board/view/?id=programming&no=668663&page=2&search_pos=&s_type=search_all&s_keyword=츄럴
[CS:APP 11] The Memory Hierarchy
https://gall.dcinside.com/board/view/?id=programming&no=669079&page=1&search_pos=&s_type=search_all&s_keyword=츄럴
-------------------------------------------------------------
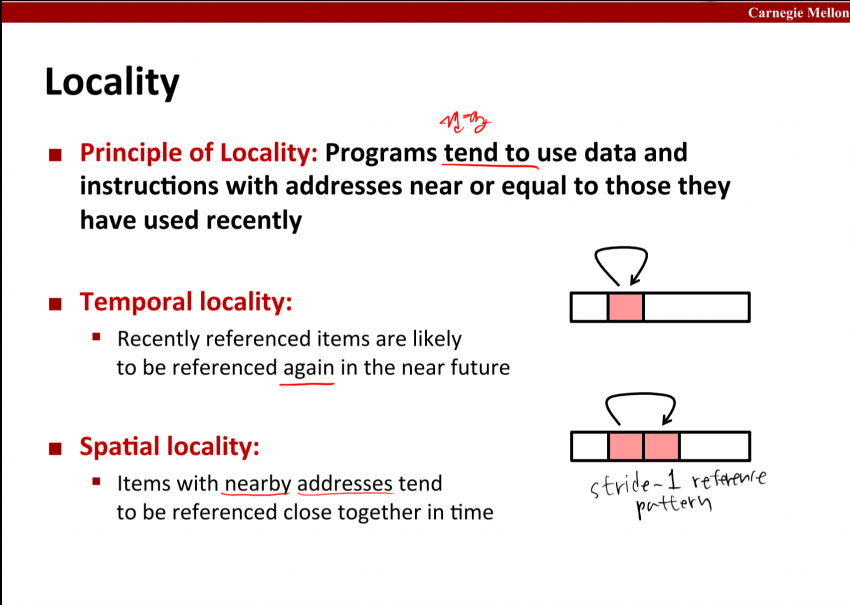
11화에서도 말했듯이, 프로그램이 나타내는 지역성에는 두가지가 있다.
하나는 temporal locality: 어떤 주소의 데이터를 반복해서 참조하는 것이다.
하나는 spatial locality: 어떤 주소 가까이의 데이터를 참조하는 것이다.
프로그램을 만들고 보니 이런 지역성이 나타나서, 하드웨어 설계자들은 이걸 이용해서 성능을 올리기 위해
cache라는 것을 만들어 낸다.

temporal locality를 잘 써먹으면 성능을 올릴 수 있다는 것은, cache라는 것이 존재한다는 것만 알아도 알 수 있다.
훨씬 빠른 저장장치에 이미 저장된 데이터를 여러번 울궈먹으면 당연히 성능이 올라갈 것이다.

참고로 cache memory는 아예 CPU안에 박혀 있다.
그런데 프로그램에 spatial locality가 있으면 왜 성능이 향상될까?
잠시 한번 생각해 보자...
.
.
.
.
.
.
.
.
.
.
.
사실 이전 그림의 단순한 cache memory 구조로는 spatial locality에 의한 성능 향상의 원인을 알 수가 없다.
실제 캐시메모리가 작동하는 방식과 좀 더 자세한 내막을 알아야만 그 원인을 파악할 수 있다.
아마 하드웨어 제조자들이 프로그램에 spatial locality가 빈번하게 나타난다는 것을 알아채고
다음과 같은 구조와 기능을 갖도록 cache memory를 설계했을 것이다.
cache memory는 개념적으로는 bit들을 저장할 수 있는 2차원 배열이다.
이 2차원 배열에다가 하부 hierarchy에 있는 저장장치의 데이터들을 가져와서 임시로 저장한다.
(즉 main memory의 데이터들을 가져와 저장한다)
그런데 데이터들을 마구잡이로 담을 수는 없으니까 데이터 저장의 규칙을 세우기 위해 이 비트들을 쪼갠다.
2차원 배열을 S개의 set(행)으로 나누고
나뉘어진 S개의 set을 또 E개의 line들로 나눈다. 그러면 이 캐시메모리에는 S*E개의 line이 있다.
각 line 하나는 3가지 영역으로 나누어진다.
1. valid bit v: 이 비트는 현재 line에 있는 데이터가 하부 hierarchy에서 가져온 데이터들인지 판별해 준다. 1이면 valid하다는 것.
2. tag bits tag: 이 비트들은 데이터를 캐시에 쓰고 읽는데 필요하다
3. cache block : 이 바이트들이 바로 데이터가 저장되는 부분이다. 이 구조를 통해서 spatial locality를 이용한다.
여기서 cache block에 주목하라. 이 바이트열 때문에 spatial locality가 중요해진다.
일단 이건 나중에 다시 설명하겠다.
그럼 이렇게 생긴 캐시 메모리에서 어떻게 데이터를 읽어올까?
CPU는 메모리에서 데이터를 읽고 싶으면 저장장치 쪽으로 메모리 주소를 발싸한다.
걔는 메모리가 어떻게 생겼는지는 별로 관심이 없다. 일단 데이터만 가져다주면 되는 것임.
일진이 빵셔틀에게 관심이 있겠는가?
여튼 CPU에서 어떤 메모리 주소(64bits)를 캐시쪽으로 발싸했다고 생각하자.
그럼 여기서 다음을 알 수 있다
1. 이 메모리 주소의 데이터를 캐시가 가지고 있으면 cache hit! 빵셔틀cache은 주머니에 있던 빵data을 일진 CPU에게 바로 줄 수 있다
2. 이 메모리 주소의 데이터를 캐시가 가지고 있지 않으면 cache miss! 빵셔틀cache은 매점main memory에 달려가서 빵data을 사와야 한다! ㅠㅠ
주소를 표현한 비트들을 3가지 부분으로 나눈다.
세 부분의 bits 중 t,s를 이용하여 캐시에 이 주소의 데이터가 저장되어 있는지 판단하고
마지막 b bits를 이용하여 캐시의 line의 블럭 어디서 부터 데이터를 읽을지 정한다.
1) 먼저 s bit들로 이 주소가 캐시의 어느 set에 있는지 판단한다.
2-1) 주소의 t bits와 1)에서 정한 set 안의 line들의 tag들과 비교한다. 이 비교는 t bits == tag가 나올 때까지 한다.
2-2) t bits == tag인 line을 1)에서 찾은 set 안에서 찾아냈으며 그 line의 valid하다면(valid bit v == 1) cache hit이다!
끝까지 비교해 보았으나 주소의 t bits == tag 인 line이 set에 존재하지 않았다면 cache miss이다!
데이터가 캐시에 없다할지라도 요청한 CPU에게는 데이터를 줘야하니까... 캐시는 하부 메모리에서 값을 가져와야 한다.
이 경우 set안의 line 중 하나를 골라서 데이터를 비우고 하부 메모리에서 값을 가져와 덮어 쓴다.
이 때 어느 line을 고르느냐는 하드웨어 만든 놈 맘대로(replacement policy)인데, 보통 가장 덜 참조되는 line을 고른다(Least Recently Used, LRU)
3)마지막으로 주소의 b bits를 이용하여 cache block에서 어느 바이트부터 읽을지 정한다.
이렇게 하여 캐시를 읽을 수 있다.
그리고 이제는 알 수 있다.
캐시는 어떻게 해서 프로그램의 spatial locality를 통해 성능을 향상시키는가?
왜 stride-1 reference pattern이 stride-2 reference pattern보다 이론적으로는 약 2배 빠른가?
그것은 cache block의 존재, 그리고 cache를 읽는 방식 때문이다!
예를 들어 stride-1 과 stride-2를 비교해 보자.
10개짜리 char배열에 접근하여 데이터를 캐시에서 CPU로 가져올 때,
캐시 블럭의 크기가 5 byte라고 하자. 그러면 다음과 같은 그림을 그릴 수 있다.
그래서 stride-1이 이론적으로는 2배쯤 성능이 높은 것이다.
이렇게 하드웨어 제조사는 cache block이라는 구조를 만들어서, 프로그램의 spatial locality를 활용하여 성능을 올렸다.
...솔직히 이 부분의 제 설명이 잘 이해가 될지 모르겠습니다.
CMU에서 제공하는 ppt를 같이 올릴테니 거기서 슬라이드쇼 한번 보시면 이해가 빠르실 거 같습니다.
글 하나로 이번 강의 내용을 다 정리하려 했는데 어렵겠네요
이제 제일 중요한 코딩 팁 같은 걸 적어야 하는데 디시가 그림 10장 제한 때문에...
마지막으로 지금껏 설명한 캐시 메모리가 인텔 최신 i7 CPU에서 어떻게 박혀 있는지 보여드리고
다음 글에서 캐시가 중요한 이유랑 코딩 팁, 최적화 방식을 올리겠습니다.
실제로는 이렇게생긴 애들이 계층구조를 이룹니다...
L0에 데이터가 없으면 L1에서 가져오고, 거기에도 없으면 L2에도 가져오고, 거기에도 없으면 L3, 거기에도 없으면
최악으로 메인메모리까지 내려가서 가져옵니다. 이거 완전 다단계
일단 끗






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
댓글 영역
획득법
① NFT 발행
작성한 게시물을 NFT로 발행하면 일주일 동안 사용할 수 있습니다. (최초 1회)
② NFT 구매
다른 이용자의 NFT를 구매하면 한 달 동안 사용할 수 있습니다. (구매 시마다 갱신)
사용법
디시콘에서지갑연결시 바로 사용 가능합니다.